1. There are two levels of perf. tuning ; one is at the application level and other is at the database level.
2. Application Tuning - deals with the tuning of applications like forms, reports; an application is a program which interacts with the database and hense
application tuning involves controlling the frequency and amount of data the app requests the database to send and receive.
3. Pointers for application tuning
3.1 Generate EXPLAIN PLAN for all the queries used in the application and ensure tuning is done.
3.2 Generate EXPLAIN PLAN for the db views as well. Views actually are complex compared to tables as actually a DB request to a view is
translated into a table call internally. And a view might have its own joins so can itself hamper performance if not created correctly. Also take due note if you
have joins of views in the queries.
3.3 As the size of data increases, there may be a need to create indexes on table columns to ensure performance. But it also involves ensuring
that the queries use the indexes created and there are not too many indexes created.
3.4 Always prefer to use PK or indexed columns.
3.5 Use specific scenarios to ensure good throughput. Ex- using ROWID is better compared to using the LIKE operator.
3.6 Reuse the queries as much as possible as it facilitates the use of shated SQL which helps improve performance.
3.7 Always remember -"Tuning does not solve the problems of poor design"
4. Pointers for database tuning
4.1 At DB level, there can three areas where tuning can be done -
4.1.1 Memory Tuning - cache and buffers
4.1.2 I/O Tuning - data access efficient
4.1.3 Contention Tuning - resolve resource availability issues
4.2 Four basic steps involved in the process of DB tuning which are true for all the above mentioned three areas -
4.2.1 Gather information
4.2.2 Determine optimal changes
4.2.3 Implement changes
4.2.4 Monitor database
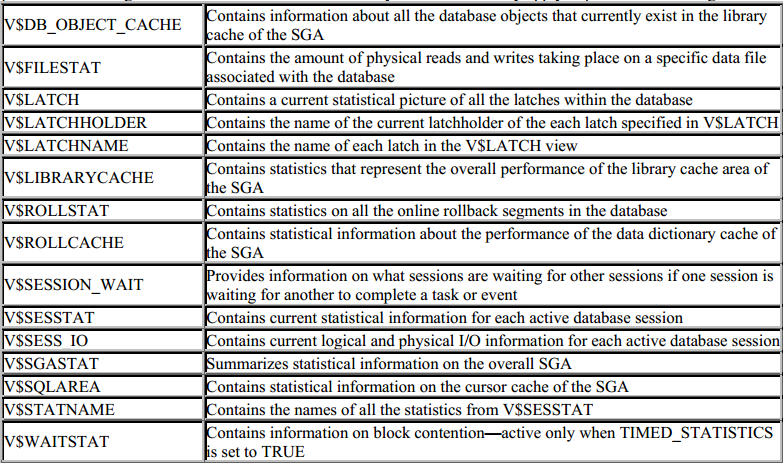
5. Performance Tools
6. Begin Statistics Utility (UTLBSTAT) and End Statistics Utility(UTLESTAT)
These scripts help in taking snapshot of oracle instance at a specific interval of time. They use oracle's dynamic performance views(V$) to gather this info.
First, utlBstat is run and after that oracle instance starts gathering all the performance statistics. It keeps on doing that until instance is stopped or utlEstat
is run. After you run utlEstat, the DB creates a REPORTS.TXT file which contains all the statistical info gathered.
7. EXPLAIN PLAN
This utility helps DBA to pass a query to optimizer and see how it performs within it.
To run explain plan, you must have a table created in your schema where you want to gather the statistics.
>$ORACLE_HOME/rdbms/admin/utlxplain.sql;
The query used to get the explain plan for any sql statement is:
EXPLAIN PLAN
SET STATEMENT_ID = 'QUERY1'
INTO CORE_TABLE FOR
SELECT transid, policyno, canx_code
FROM policy
WHERE policyno = 100;
Explain plan works for only DML statements.
8. SQL*Trace and TKPROF
Unlike explain plan which only generates the query execution path of the optimizer; sqlTrace also generates info like the cpu usage, no of rows fetched
etc.
Parameters which need to be set in INIT.ORA file before you can run sqlTrace are: MAX_DUMP_FILE_SIZE - max size of the trace file, SQL_TRACE - makes
a trace result to be written to file for every database user; not preferred though, USER_DUMP_DEST - destination where the dump files are written.
ALTER SESSION SET SQL_TRACE = TRUE; The syntax of the query used to start sqlTrace in sql session.
For generating the trace file for an application, we can use the PLSQL code; the syntax is:
BEGIN
DBMS_SESSION.SET_SQL_TRACE(TRUE);
-- the code goes here whose statistics are to be gathered
DBMS_SESSION.SET_SQL_TRACE(FALSE);
END
Once the file is generated , it needs to be converted into a readable format. TKPROF utility is used for that. The syntax -
% tkprof trace_file.trc new_file.log
TKPROF utility converts the unreadable trc file into a log file. There are certain optional parameters present in the syntax.
EXPLAIN - username password
INSERT - where to dump both the sql statements and data for each statement
PRINT - no of queries to be picked in the trace file
RECORD - specify the output file
SORT - order the results of tkprof
9. With both explain plan and trace files, few pointers help to estimate the performance parameters:
9.1 There should be a few logical I/O blocks versus a large no of rows returned. Optimal ratio is 2:1
9.2 mostly, execute value should be higher than the parse value. but if no of parses is higher compared to the no of executions, try incresing the
size of the shared pool.
9.3 No of logical I/O should be higher compared to the physical I/O.
10. Dynamic performance tables - are actually views despite the name.
are created when the db instance starts.
these are SGA held memory structures.
useful for perf. tuning and backup and recovery.